即刻App年轻人的同好社区
下载
 置顶
置顶很多朋友最近老问我一些我之前写过的东西在哪里,所以整理了一下写个置顶贴,内容会定期更新:
1️⃣ 我运营的 AIGC 周刊每周一更新,主要内容是上周 AI 领域的重点动态解析以及相关的产品和文章:
op7418.zhubai.love
2⃣️ 我的Midjourney作品汇总和对应的提示词:
walling.app
3⃣️ 我开发的一些产品
帮你将 Midjourney 的图片和提示词快速收集到你的 Notion 数据库中:
mp.weixin.qq.com
帮你自动分段翻译 Midjoureny 官网的提示词:
mp.weixin.qq.com
利用 ChatGPT 自动监控对应领域的信息并处理和发送到Discord 频道:
op7418.zhubai.loveposts/2251721691841511424
4⃣️ 我写的一些教程
AI 歌手系列课程教你使用和训练自己的 AI 歌手模型:
mp.weixin.qq.com
mp.weixin.qq.com
Stable Diffusion 保姆级入门教程包括 Web UI 的部署和 LoRA 模型的使用:
op7418.zhubai.loveposts/2238998671356555264
op7418.zhubai.loveposts/2239983151969951744
Stable Diffusion 模型大神工作流解析:
mp.weixin.qq.com
web.okjike.com
教你十几分钟不用代码创建自己的AI应用
mp.weixin.qq.com
1️⃣ 我运营的 AIGC 周刊每周一更新,主要内容是上周 AI 领域的重点动态解析以及相关的产品和文章:
op7418.zhubai.love
2⃣️ 我的Midjourney作品汇总和对应的提示词:
walling.app
3⃣️ 我开发的一些产品
帮你将 Midjourney 的图片和提示词快速收集到你的 Notion 数据库中:
mp.weixin.qq.com
帮你自动分段翻译 Midjoureny 官网的提示词:
mp.weixin.qq.com
利用 ChatGPT 自动监控对应领域的信息并处理和发送到Discord 频道:
op7418.zhubai.loveposts/2251721691841511424
4⃣️ 我写的一些教程
AI 歌手系列课程教你使用和训练自己的 AI 歌手模型:
mp.weixin.qq.com
mp.weixin.qq.com
Stable Diffusion 保姆级入门教程包括 Web UI 的部署和 LoRA 模型的使用:
op7418.zhubai.loveposts/2238998671356555264
op7418.zhubai.loveposts/2239983151969951744
Stable Diffusion 模型大神工作流解析:
mp.weixin.qq.com
web.okjike.com
教你十几分钟不用代码创建自己的AI应用
mp.weixin.qq.com
221 13102
Synthesia 即将推出数字人头像新模型 EXPRESS-1。
类似 HeyGen 的数字人头像,不过这个可以根据文本能精准模仿人类的微表情和身体语言。
他们的表现会根据剧本情绪——悲伤时看起来和听起来都悲伤,兴奋时则显得活泼有力。
这里尝试:www.synthesia.io
类似 HeyGen 的数字人头像,不过这个可以根据文本能精准模仿人类的微表情和身体语言。
他们的表现会根据剧本情绪——悲伤时看起来和听起来都悲伤,兴奋时则显得活泼有力。
这里尝试:www.synthesia.io
01:04
13 04
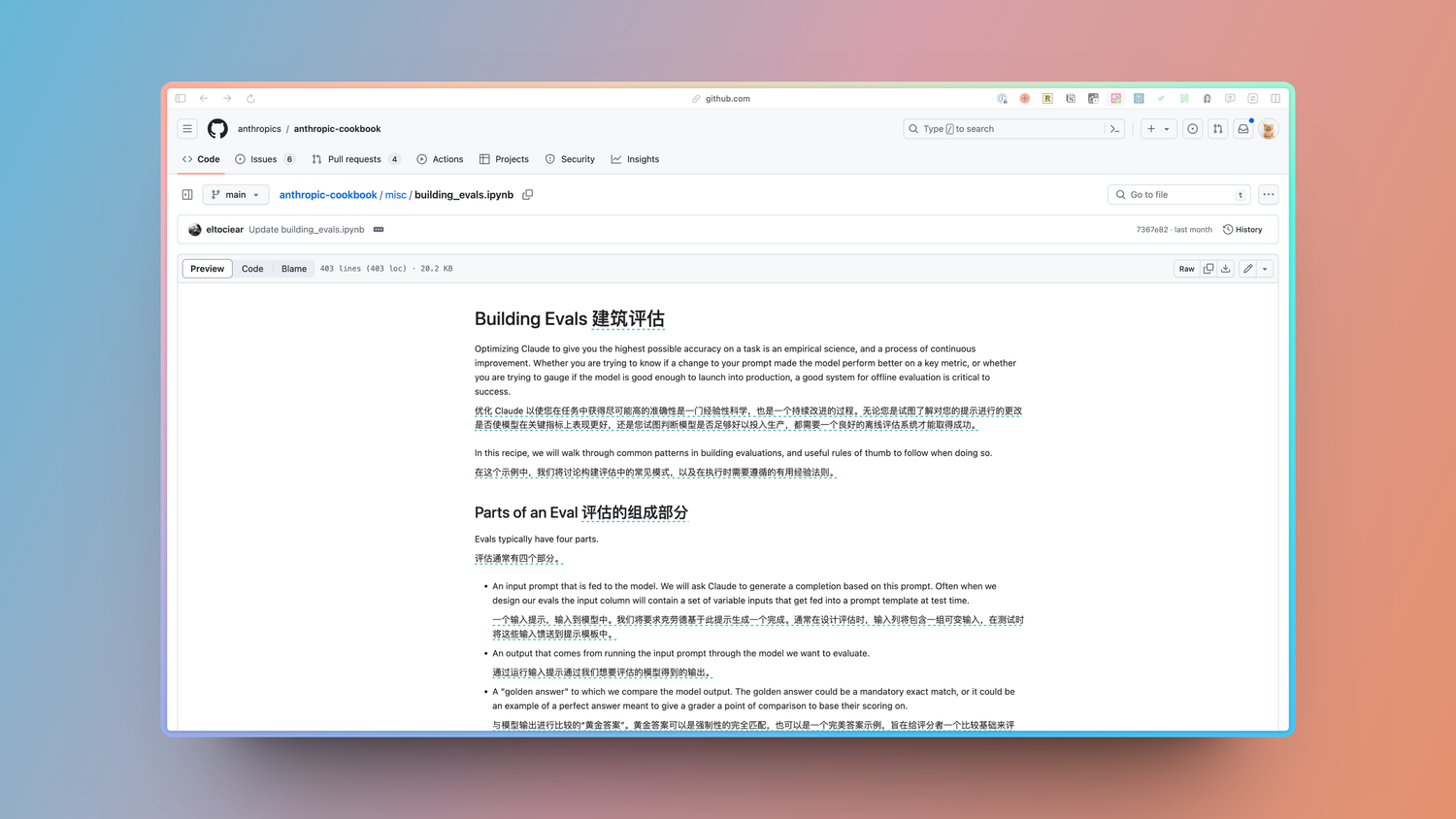
Anthropic 这个教程教你如何创建一个自己的语言模型评估测试集。
1️⃣LLM 评估 体系通常包含4个部分:
输入提示集
模型对这些提示的响应
用来与模型输出对比的“标准答案”
根据某种评分方法得出的分数
2️⃣前三部分相当直观 —— 你需要写一些提示,为每个提示编写理想答案,并在你正在评估的模型上测试这些提示。
3️⃣第四部分(基于某种评分方法的分数)可能有些棘手。有3种常见的评分方法:
代码:代码:使用代码来检查精确匹配或关键短语(快速且可靠)
人工:人工比较输出与标准答案(较慢且成本高)
模型:利用大语言模型(LLM)来评估输出
选择哪种评分方法取决于你的具体任务。
理想情况下,基于模型的评分方法可以实现自动化,随着模型智能的提升,这一方法越来越可行。
要改进基于模型的评分效果,可以将其视为一个迭代过程。
先手动评分5至10个输出,将这些评分与模型的评分结果进行比较,然后调整评分提示,使模型的评分更加符合你的标准。
另一个建议是:有时候使用与被评估模型不同的模型来进行评分更为合适。
4️⃣其他建议:
务必构建一个多样化的测试集,以涵盖你任务中的常见场景。
通过将输出设计为容易验证的形式(例如多项选择题)来设计更易于评分的评估工具。
他们 CookBook 里面有更详细的评估创建步骤和代码:github.com
1️⃣LLM 评估 体系通常包含4个部分:
输入提示集
模型对这些提示的响应
用来与模型输出对比的“标准答案”
根据某种评分方法得出的分数
2️⃣前三部分相当直观 —— 你需要写一些提示,为每个提示编写理想答案,并在你正在评估的模型上测试这些提示。
3️⃣第四部分(基于某种评分方法的分数)可能有些棘手。有3种常见的评分方法:
代码:代码:使用代码来检查精确匹配或关键短语(快速且可靠)
人工:人工比较输出与标准答案(较慢且成本高)
模型:利用大语言模型(LLM)来评估输出
选择哪种评分方法取决于你的具体任务。
理想情况下,基于模型的评分方法可以实现自动化,随着模型智能的提升,这一方法越来越可行。
要改进基于模型的评分效果,可以将其视为一个迭代过程。
先手动评分5至10个输出,将这些评分与模型的评分结果进行比较,然后调整评分提示,使模型的评分更加符合你的标准。
另一个建议是:有时候使用与被评估模型不同的模型来进行评分更为合适。
4️⃣其他建议:
务必构建一个多样化的测试集,以涵盖你任务中的常见场景。
通过将输出设计为容易验证的形式(例如多项选择题)来设计更易于评分的评估工具。
他们 CookBook 里面有更详细的评估创建步骤和代码:github.com
12 06
Open AI 昨晚的两条内容,首先是介绍了为企业 API 客户做的一些功能上的更新,基本上前几天都说过了就是总结一下。#ai# #openai#
包括更多企业安全措施、更好的 API 控制、Assistants API的一系列更新和节约成本的措施。
另外还久违的发布了一篇关于模型安全的论文,帮助减少 LLM 提示注入和越狱在内的多种攻击。
🌟企业 API 客户做的一些功能上的更新包括:
推出 Private Link,客户可以确保 Azure 和 OpenAI 之间直接通信的新方式,最大限度地减少对开放互联网的暴露。
发布了原生的多因素身份验证(MFA),以帮助确保符合日益增加的访问控制要求。
组织将能够更精细地控制和监督 OpenAI 中的个别项目。这包括将角色和 API 密钥范围限定于特定项目,限制/允许提供哪些模型,设置基于使用量和速率的限制以提供访问权限并避免意外超支。
Assistants API 引入了几项更新,以实现更准确的检索、围绕模型行为和用于完成任务的工具的灵活性,以及更好地控制成本。
达到承诺的每分钟 Token 吞吐量的客户可以获得 5%-10% 的折扣。
客户可以使用新批处理 API 异步运行非紧急工作负载。批处理 API 请求的定价为共享价格的 50%,提供更高的速率限制,并在 24 小时内返回结果。
🌟训练LLM优先考虑特权指令,避免越狱的措施包括:
造成这种漏洞的一个主要原因是,LLM往往无法区分来自系统的指令和来自不可靠用户或第三方的文本,对它们给予相同的优先级处理。
为此,我们设计了一种指令优先级系统,明确规定了在不同优先级指令发生冲突时,模型应如何响应。
接着,我们开发了一种自动数据生成技术,通过这种技术,可以训练LLM在处理指令时有选择性地忽视那些权限较低的指令。
应用这种方法后,我们发现它显著增强了LLM的安全性,即便面对训练阶段未曾遇到的新型攻击,也能保持高度的鲁棒性,同时对模型的常规功能几乎没有影响。
公告地址:openai.com
论文地址:arxiv.org
包括更多企业安全措施、更好的 API 控制、Assistants API的一系列更新和节约成本的措施。
另外还久违的发布了一篇关于模型安全的论文,帮助减少 LLM 提示注入和越狱在内的多种攻击。
🌟企业 API 客户做的一些功能上的更新包括:
推出 Private Link,客户可以确保 Azure 和 OpenAI 之间直接通信的新方式,最大限度地减少对开放互联网的暴露。
发布了原生的多因素身份验证(MFA),以帮助确保符合日益增加的访问控制要求。
组织将能够更精细地控制和监督 OpenAI 中的个别项目。这包括将角色和 API 密钥范围限定于特定项目,限制/允许提供哪些模型,设置基于使用量和速率的限制以提供访问权限并避免意外超支。
Assistants API 引入了几项更新,以实现更准确的检索、围绕模型行为和用于完成任务的工具的灵活性,以及更好地控制成本。
达到承诺的每分钟 Token 吞吐量的客户可以获得 5%-10% 的折扣。
客户可以使用新批处理 API 异步运行非紧急工作负载。批处理 API 请求的定价为共享价格的 50%,提供更高的速率限制,并在 24 小时内返回结果。
🌟训练LLM优先考虑特权指令,避免越狱的措施包括:
造成这种漏洞的一个主要原因是,LLM往往无法区分来自系统的指令和来自不可靠用户或第三方的文本,对它们给予相同的优先级处理。
为此,我们设计了一种指令优先级系统,明确规定了在不同优先级指令发生冲突时,模型应如何响应。
接着,我们开发了一种自动数据生成技术,通过这种技术,可以训练LLM在处理指令时有选择性地忽视那些权限较低的指令。
应用这种方法后,我们发现它显著增强了LLM的安全性,即便面对训练阶段未曾遇到的新型攻击,也能保持高度的鲁棒性,同时对模型的常规功能几乎没有影响。
公告地址:openai.com
论文地址:arxiv.org

6 00
可以识别对话客户情感的 EVI 正式发布了API。
在发布这段时间里生成了~100K 对话,平均对话时长10分钟,生成超过 3 百万条消息。
EVI 的特点有:
✨ 提供转录、语言模型构建以及生动的语音合成(TTS)服务
🗣️ 高品质声音,音调和音量富于人性化的变化
💬 支持用户打断和自动检测谈话结束
🫶 理解和生成具有共情力的表达
EVI API 还有一些新的能力:
⌨️ 系统提示:可自定义AI的个性、回答风格及话语内容
💬 支持使用其他大语言模型:支持 Fireworks Mixtral8x7b、所有 OpenAI 模型及 Anthropic 模型
✨ 使用自己的大语言模型或其他方式生成文本:通过 WebSocket 连接,将的文本生成服务器与EVI API 对接
🫶 使用 EVI 的富有表现力的声音,只需向 API 发送文本即可实现语音输出
API 文档:beta.hume.ai
在发布这段时间里生成了~100K 对话,平均对话时长10分钟,生成超过 3 百万条消息。
EVI 的特点有:
✨ 提供转录、语言模型构建以及生动的语音合成(TTS)服务
🗣️ 高品质声音,音调和音量富于人性化的变化
💬 支持用户打断和自动检测谈话结束
🫶 理解和生成具有共情力的表达
EVI API 还有一些新的能力:
⌨️ 系统提示:可自定义AI的个性、回答风格及话语内容
💬 支持使用其他大语言模型:支持 Fireworks Mixtral8x7b、所有 OpenAI 模型及 Anthropic 模型
✨ 使用自己的大语言模型或其他方式生成文本:通过 WebSocket 连接,将的文本生成服务器与EVI API 对接
🫶 使用 EVI 的富有表现力的声音,只需向 API 发送文本即可实现语音输出
API 文档:beta.hume.ai
00:59
6 17
Adobe 发布了Firefly Image 3的正式更新公告,详细介绍了一下模型升级的细节:
新模型可以生成更高质量的图像,更好地解释提示,自动应用与提示匹配的样式,并在图像中提供更准确的文本。
Image 3 Model 还与结构参考和样式参考功能一起工作,提供出色的用户控制和最先进的视觉质量。
Image 3 Model 更好地理解文本提示和场景,实现更好地反映长、复杂提示并包含更丰富细节(包括文本)的图像生成。
在 Firefly web 应用程序的生成填充模块中引入了生成扩展功能。这通过允许更改原始图像的长宽比或大小。
来源:blog.adobe.com
新模型可以生成更高质量的图像,更好地解释提示,自动应用与提示匹配的样式,并在图像中提供更准确的文本。
Image 3 Model 还与结构参考和样式参考功能一起工作,提供出色的用户控制和最先进的视觉质量。
Image 3 Model 更好地理解文本提示和场景,实现更好地反映长、复杂提示并包含更丰富细节(包括文本)的图像生成。
在 Firefly web 应用程序的生成填充模块中引入了生成扩展功能。这通过允许更改原始图像的长宽比或大小。
来源:blog.adobe.com
9 13

9 10
Meta 在雷朋 Meta 眼镜上推出了多模态的 Meta AI。
Meta AI 可以获取到眼镜摄像头的内容并对你的语音问题提供回复。
说明多模态的 Llama3 已经训练完成了啊,小扎吃独食。
来源:x.com
Meta AI 可以获取到眼镜摄像头的内容并对你的语音问题提供回复。
说明多模态的 Llama3 已经训练完成了啊,小扎吃独食。
来源:x.com
00:12
16 24
Adobe 在今天的 Adobe Max 大会上正式更新了 Firefly Image 3 图像生成模型。
大概试了一下进步非常大,除了一些特殊概念之外跟 Midjoureny V6 差不多了,而且也支持提示词优化。
新增了使用参考图像、创造背景、生成相似图像、细节增强等功能。
今天就可以在 PS 测试版和网页版 Firefly 中使用。
在这里体验Firefly Image 3:firefly.adobe.com
大概试了一下进步非常大,除了一些特殊概念之外跟 Midjoureny V6 差不多了,而且也支持提示词优化。
新增了使用参考图像、创造背景、生成相似图像、细节增强等功能。
今天就可以在 PS 测试版和网页版 Firefly 中使用。
在这里体验Firefly Image 3:firefly.adobe.com




29 213
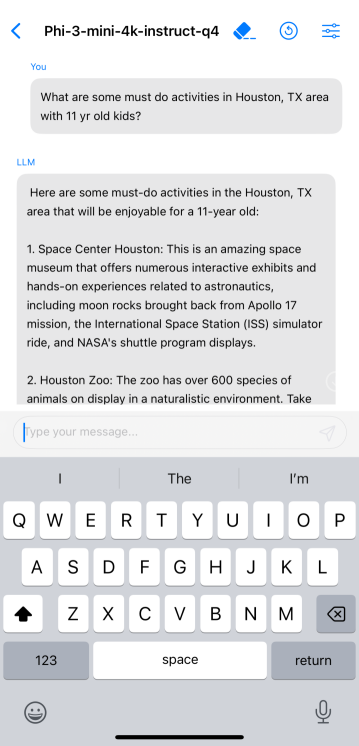
微软的这个 phi-3-mini 模型有点强啊。
4 位量化之后可以部署在 iPhone 14 上,只占用 1.8G 内存,每秒输出 12 个 Token 。
关键他们说这个模型能力上跟 Mixtral 8x7B 和 GPT-3.5 差不多。
详细介绍:
一个新型语言模型 phi-3-mini,该模型拥有38亿参数,训练数据高达3.3万亿 Token。
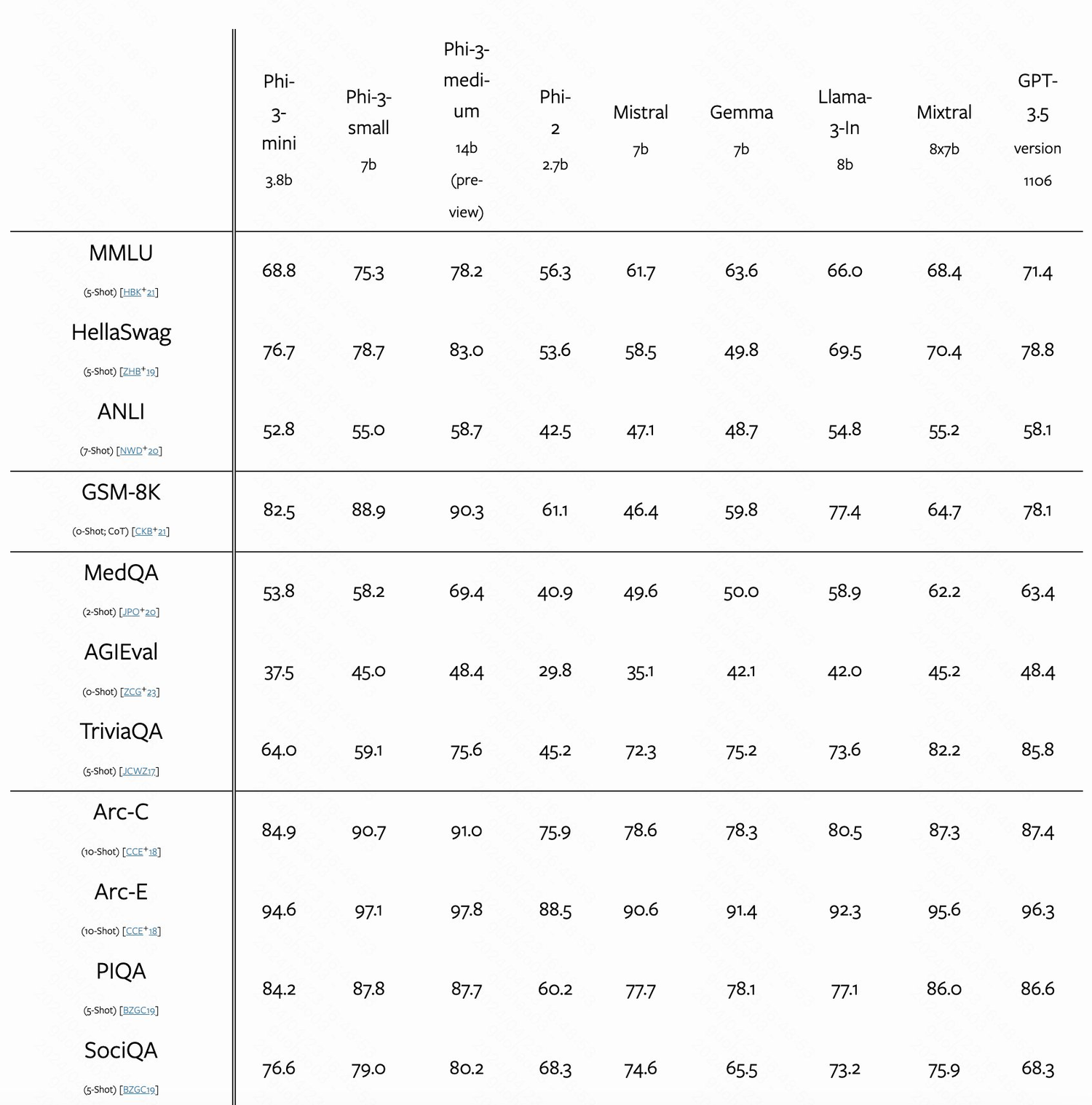
根据学术基准和我们的内部测试,phi-3-mini 的整体性能与 Mixtral 8x7B 和 GPT-3.5 等大型模型相当(例如,在 MMLU 测试中达到69%,在 MT-bench 测试中得分为8.38),但其体积小到足以部署在手机上。
这种创新归功于我们的训练数据集,它是 phi-2 所用数据集的扩大版本,包括了经过严格筛选的网络数据和合成数据。此外,这个模型还进一步优化了其鲁棒性、安全性和适应聊天的格式。
我们还初步展示了在训练达4.8万亿 Token 的情况下,使用7B和14B参数的模型(名为 phi-3-small 和 phi-3-medium)所取得的成效,这两个模型的性能均显著优于 phi-3-mini(例如,在 MMLU 测试中分别达到75%和78%,在 MT-bench 测试中分别得分为8.7和8.9)。
技术报告地址:arxiv.org
4 位量化之后可以部署在 iPhone 14 上,只占用 1.8G 内存,每秒输出 12 个 Token 。
关键他们说这个模型能力上跟 Mixtral 8x7B 和 GPT-3.5 差不多。
详细介绍:
一个新型语言模型 phi-3-mini,该模型拥有38亿参数,训练数据高达3.3万亿 Token。
根据学术基准和我们的内部测试,phi-3-mini 的整体性能与 Mixtral 8x7B 和 GPT-3.5 等大型模型相当(例如,在 MMLU 测试中达到69%,在 MT-bench 测试中得分为8.38),但其体积小到足以部署在手机上。
这种创新归功于我们的训练数据集,它是 phi-2 所用数据集的扩大版本,包括了经过严格筛选的网络数据和合成数据。此外,这个模型还进一步优化了其鲁棒性、安全性和适应聊天的格式。
我们还初步展示了在训练达4.8万亿 Token 的情况下,使用7B和14B参数的模型(名为 phi-3-small 和 phi-3-medium)所取得的成效,这两个模型的性能均显著优于 phi-3-mini(例如,在 MMLU 测试中分别达到75%和78%,在 MT-bench 测试中分别得分为8.7和8.9)。
技术报告地址:arxiv.org
17 15